搜索到
16
篇与
的结果
-
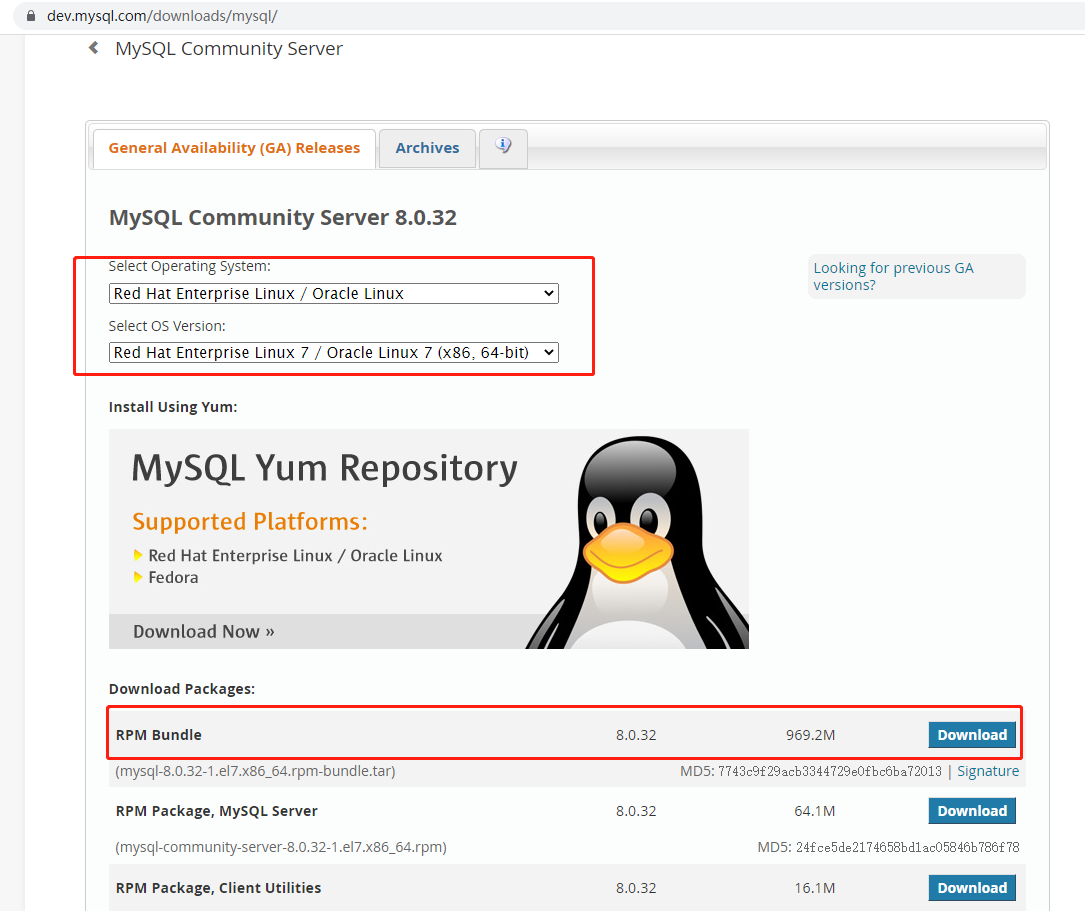
 RedHat7.6安装mysql8步骤 1、官网下载mysql安装包直达链接:https://dev.mysql.com/downloads/mysql/2、将下载好的安装包上传到redhat系统上用wget下载比较慢,可能是cdn的问题3、安装前需要先卸载自带的mariadb和原有的mysql1、卸载mariadb: yum remove mariadb rpm -e mariadb-libs-5.5.60-1.el7_5.x86_64 --nodeps 2、删除配置文件: rm -f /etc/my.cnf 3、删除数据目录: rm -rf /var/lib/mysql/4、解压安装包(根据自己的包名修改)tar -xvf mysgl-8.0.32-1.e17.x86_64.rpm-bundle.tar5、 安装必要的rpm包rpm -ivh mysql-community-common-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-client-plugins-8.0.32-1.el7.x86_64.rpm (注意这个装完才能装下面一个,否则会报错) rpm -ivh mysql-community-libs-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-compat-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-icu-data-files-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-client-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-server-8.0.32-1.el7.x86_64.rpm(注意上面两个装完才能装这个)6、配置my.cnf文件(可选项,如果不需要可跳过,但是建议)在mysql启动初始化前,一定要确认根据自己所需的MySQL参数,是否需要修改my.cnf文件,比如区分表名大小写,在MySQL8.0之前,是可以在mysql启动后进行重新修改的,但是8.0之后,只能在MySQL启动前进行配置,所以强烈建议,在第一次初始化启动MySQL前,先进行配置my.cnf可参考:https://blog.csdn.net/gzt19881123/article/details/109511245 进行配置7、执行MySQL初始化,并获取root账户初始密码依次执行命令: 初始化mysql:mysqld --initialize --user=mysql --lower_case_table_names=1 获取密码:grep "password" /var/log/mysqld.log8、启动MySQL服务systemctl start mysqld systemctl status mysqld systemctl enable mysqld9、使用默认密码登陆mysqlmysql -u root -p10、修改root密码使用默认密码登陆后,需要强制修改初始化默认的登陆密码,不然会报错ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456'; FLUSH PRIVILEGES;11、配置mysql允许远程访问(可选)依次执行下列SQL进行修改允许USE mysql; UPDATE mysql.user SET host = '%' WHERE user = 'root'; SELECT user, host, plugin, authentication_string FROM mysql.user; FLUSH PRIVILEGES;12、防火墙放行3306端口# 永久开放3306端口 firewall-cmd --permanent --zone=public --add-port=3306/tcp # 重启防火墙 systemctl restart firewalld # 检测设定是否生效 iptables -L -n | grep 3306
RedHat7.6安装mysql8步骤 1、官网下载mysql安装包直达链接:https://dev.mysql.com/downloads/mysql/2、将下载好的安装包上传到redhat系统上用wget下载比较慢,可能是cdn的问题3、安装前需要先卸载自带的mariadb和原有的mysql1、卸载mariadb: yum remove mariadb rpm -e mariadb-libs-5.5.60-1.el7_5.x86_64 --nodeps 2、删除配置文件: rm -f /etc/my.cnf 3、删除数据目录: rm -rf /var/lib/mysql/4、解压安装包(根据自己的包名修改)tar -xvf mysgl-8.0.32-1.e17.x86_64.rpm-bundle.tar5、 安装必要的rpm包rpm -ivh mysql-community-common-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-client-plugins-8.0.32-1.el7.x86_64.rpm (注意这个装完才能装下面一个,否则会报错) rpm -ivh mysql-community-libs-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-compat-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-icu-data-files-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-client-8.0.32-1.el7.x86_64.rpm rpm -ivh mysql-community-server-8.0.32-1.el7.x86_64.rpm(注意上面两个装完才能装这个)6、配置my.cnf文件(可选项,如果不需要可跳过,但是建议)在mysql启动初始化前,一定要确认根据自己所需的MySQL参数,是否需要修改my.cnf文件,比如区分表名大小写,在MySQL8.0之前,是可以在mysql启动后进行重新修改的,但是8.0之后,只能在MySQL启动前进行配置,所以强烈建议,在第一次初始化启动MySQL前,先进行配置my.cnf可参考:https://blog.csdn.net/gzt19881123/article/details/109511245 进行配置7、执行MySQL初始化,并获取root账户初始密码依次执行命令: 初始化mysql:mysqld --initialize --user=mysql --lower_case_table_names=1 获取密码:grep "password" /var/log/mysqld.log8、启动MySQL服务systemctl start mysqld systemctl status mysqld systemctl enable mysqld9、使用默认密码登陆mysqlmysql -u root -p10、修改root密码使用默认密码登陆后,需要强制修改初始化默认的登陆密码,不然会报错ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456'; FLUSH PRIVILEGES;11、配置mysql允许远程访问(可选)依次执行下列SQL进行修改允许USE mysql; UPDATE mysql.user SET host = '%' WHERE user = 'root'; SELECT user, host, plugin, authentication_string FROM mysql.user; FLUSH PRIVILEGES;12、防火墙放行3306端口# 永久开放3306端口 firewall-cmd --permanent --zone=public --add-port=3306/tcp # 重启防火墙 systemctl restart firewalld # 检测设定是否生效 iptables -L -n | grep 3306 -
kafka的消费组处理(消费回滚处理) 查看消费者列表--listbin/kafka-consumer-groups.sh --bootstrap-server 172.26.84.174:9092 --listpindou_device_controlpindou_gc_propindou_garbagecollection_1pindou_garbagecollection_revice查看指定消费组详情--groupbin/kafka-consumer-groups.sh --bootstrap-server 172.26.84.174:9092 --describe --group pindou_gc_probin/kafka-consumer-groups.sh --bootstrap-server 172.26.84.174:9092 --describe --group pindou_csp_pro所有消费组成员信息bin/kafka-consumer-groups.sh --describe --all-groups --members --bootstrap-server 172.26.84.174:9092指定消费组成员信息bin/kafka-consumer-groups.sh --describe --members --group pindou_gc_pro --bootstrap-server 172.26.84.174:9092所有消费组状态信息bin/kafka-consumer-groups.sh --describe --all-groups --state --bootstrap-server 172.26.84.174:9092指定消费组状态信息bin/kafka-consumer-groups.sh --describe --state --group pindou_gc_pro --bootstrap-server 172.26.84.174:9092删除指定消费组--groupsh bin/kafka-consumer-groups.sh --delete --group test2_consumer_group --bootstrap-server xxxx:9090删除所有消费组--all-groupssh bin/kafka-consumer-groups.sh --delete --all-groups --bootstrap-server xxxx:9090重置指定消费组的所有Topic的偏移量--all-topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --group test2_consumer_group --bootstrap-server xxxx:9090 --dry-run --all-topic重置指定消费组的指定Topic的偏移量--topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --group test2_consumer_group --bootstrap-server xxxx:9090 --dry-run --topic test2重置所有消费组的所有Topic的偏移量--all-topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --all-group --bootstrap-server xxxx:9090 --dry-run --all-topic重置所有消费组中指定Topic的偏移量--topicsh bin/kafka-consumer-groups.sh --reset-offsets --to-earliest --all-group --bootstrap-server xxxx:9090 --dry-run --topic test2--to-earliest : 重置offset到最开始的那条offset(找到还未被删除最早的那个offset) --to-current: 直接重置offset到当前的offset,也就是LOE --to-latest: 重置到最后一个offset --to-datetime: 重置到指定时间的offset;格式为:YYYY-MM-DDTHH:mm:SS.sss; --to-datetime "2021-6-26T00:00:00.000"--to-offset 重置到指定的offset,但是通常情况下,匹配到多个分区,这里是将匹配到的所有分区都重置到这一个值; 如果 1.目标最大offset<--to-offset, 这个时候重置为目标最大offset;2.目标最小offset>--to-offset ,则重置为最小; 3.否则的话才会重置为--to-offset的目标值; 一般不用这个 --to-offset 3465 --shift-by 按照偏移量增加或者减少多少个offset;正的为往前增加;负的往后退;当然这里也是匹配所有的; --shift-by 100 、--shift-by -100--from-file 根据CVS文档来重置; 这里下面单独讲解
-
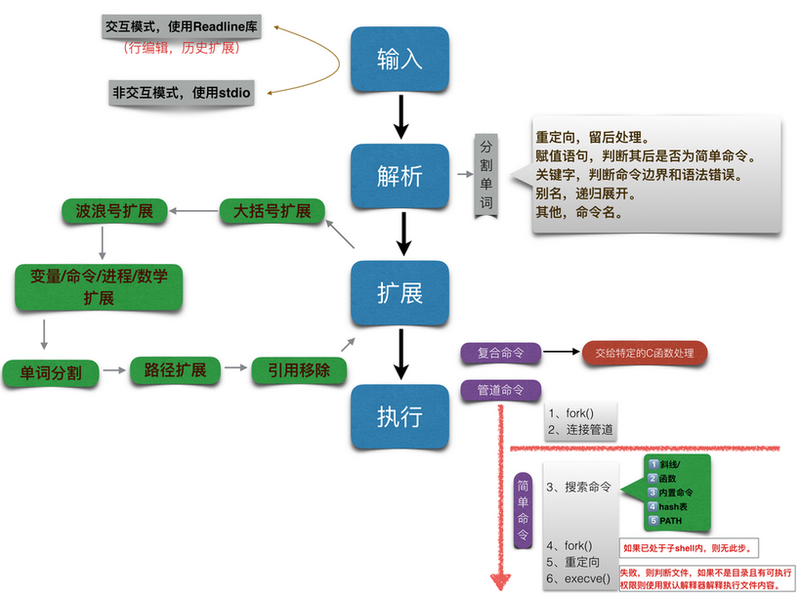
Shell 参数扩展及各类括号在 Shell 编程中的应用 文章引用自 开源中国的一位大佬的博客 Shell 参数扩展及各类括号在 Shell 编程中的应用1、bash 中的大括号参数扩展(Parameter Expansion)假设我们定义了一个变量为:file=/dir1/dir2/dir3/my.file.txt1.1 bash 下的 split 取 “数组” 的首、尾:${file#*/}:拿掉第一条 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt ${file##*/}:拿掉最后一条 / 及其左边的字符串:my.file.txt ${file#*.}:拿掉第一个 . 及其左边的字符串:file.txt ${file##*.}:拿掉最后一个 . 及其左边的字符串:txt ${file%/*}:拿掉最后条 / 及其右边的字符串:/dir1/dir2/dir3 ${file%%/*}:拿掉第一条 / 及其右边的字符串:(空值) ${file%.*}:拿掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file ${file%%.*}:拿掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/myTips:记忆的方法为:'#'是去掉左边 (在键盘上 # 在 $ 之左边)'%' 是去掉右边 (在键盘上 % 在 $ 之右边)单一符号是最小匹配﹔两个符号是最大匹配(类似贪婪匹配)。1.2 bash 下的 substring 按字符位置、长度截取${file:0:5}:提取最左边的 5 个字节:/dir1 ${file:5:5}:提取第 5 个字节右边的连续 5 个字节:/dir2 ${#file}:计算出字符串的长度,/dir1/dir2/dir3/my.file.txt 字符串长度 27 ${file: -4}:提取最后四个字符串(空格是为了避免冲突,注意不同于echo ${file:-4},也可以用(-4)代替空格),类似用法(提取前四个字符) ${file:0:4}1.3 bash 下的 replace 与 replaceAll我们也可以对变量值里的字符串作替换:${file/dir/path}:将第一个 dir 提换为 path:/path1/dir2/dir3/my.file.txt ${file//dir/path}:将全部 dir 提换为 path:/path1/path2/path3/my.file.txt1.4 bash 下的变量空值检测与初始化利用 ${} 还可针对不同的变量状态赋值 (没设定、空值、非空值):${file-my.file.txt} :假如 $file 没有设定,则使用 my.file.txt 作传回值。(空值及非空值时不作处理) ${file:-my.file.txt} :假如 $file 没有设定或为空值,则使用 my.file.txt 作传回值。 (非空值时不作处理) ${file+my.file.txt} :假如 $file 设为空值或非空值,均使用 my.file.txt 作传回值。(没设定时不作处理) ${file:+my.file.txt} :若 $file 为非空值,则使用 my.file.txt 作传回值。 (没设定及空值时不作处理) ${file=my.file.txt} :若 $file 没设定,则使用 my.file.txt 作传回值,同时将 $file 赋值为 my.file.txt 。 (空值及非空值时不作处理) ${file:=my.file.txt} :若 $file 没设定或为空值,则使用 my.file.txt 作传回值,同时将 $file 赋值为 my.file.txt 。 (非空值时不作处理) ${file?my.file.txt} :若 $file 没设定,则将 my.file.txt 输出至 STDERR。 (空值及非空值时不作处理) ${file:?my.file.txt} :若 $file 没设定或为空值,则将 my.file.txt 输出至 STDERR。 (非空值时不作处理)Tips:以上的理解在于,你一定要分清楚 unset 与 null 及 non-null 这三种赋值状态.一般而言,:与 null 有关,若不带:的话,null 不受影响,若带:则连 null 也受影响。而 - 和 = 的区别在于是否把传回值赋给引用变量,例如:${parameter:-word} word is only substituted. ${parameter:=word} word is substituted and assigned to parameter. root@localhost ~ $ echo "$var" root@localhost ~ $ echo "${var:-hello}" hello root@localhost ~ $ echo "$var" root@localhost ~ $ echo "${var:=hello}" hello root@localhost ~ $ echo "$var" hello1.5 bash 下的数组和关联数组Bash4 中可以使用两种容器。一种是数组,另一种是关联数组,类似于其他语言中的 Map/Hash/Dict。声明数组的常用语法: declare -a ARY 或者 ARY=(1 2 3)声明关联数组的唯一语法:declare -A MAP(bash4 以下不支持)赋值的语法:直接 ARY[N]=VALUE,N 可以是数字索引也可以是键。关联数组可以使用 MAP=([x]=a [y]=b) 进行多项赋值,注意这是赋值的语句而不是声明。亲测数组中的索引不一定要按顺序来,你可以先给 2 和 3 上的元素赋值。(同样算是弱类型的 Javascript 也支持这种无厘头赋值,这算通病么?)往现有数组批量添加元素:ARY+=(a b c) MAP+=([a]=1 [b]=2)取值:${ARY[INDEX]} ${MAP[KEY]}注意花括号的使用${A[@]} 展开成所有的变量,而获取数组长度使用 ${#A[@]}切片:${ARY[@]:N:M} N是offset而M是length返回索引,相当于keys():${!MAP[@]}试试下面的代码:declare -a ARY declare -A MAP MAP+=([a]=1 [b]=2) ARY+=(a b c) echo ${ARY[1]} echo ${MAP[a]} echo "${ARY[@]}" echo "${MAP[@]}" echo "${ARY[@]:0:1}" echo ${#ARY[@]} echo "${!MAP[@]}" ARY[4]=a echo ${ARY[@]} echo ${ARY[3]}1.6 bash 下的大小写变换HI=HellO echo "$HI" # HellO echo ${HI^} # HellO echo ${HI^^} # HELLO echo ${HI,} # hellO echo ${HI,,} # hello echo ${HI~} # hellO echo ${HI~~} #hELLo^大写,,小写, ~大小写切换重复一次只修改首字母,重复两次则应用于所有字母。混着用会怎样?echo ${HI^,^} # HellO看来是不行的×_×2、各类括号在 shell/bash 编程中的应用上面应该见识到了 shell 中大括号的强大功能,其实 shell 下有很多种括号,不像其它高级语言括号只起到语法和意义的作用,而 shell 下的每种括号除了语法、语义的作用之外,还对 shell 编程起到了功能上的扩展。2.1 () 在子shell中运行(a=1);echo $a,结果是空,因为a=1不是在当前shell中运行的(a=1);(echo $a)也是空的。小技巧:(cd $path, do something) 可以让不切换当前目录而在其它目录干点别的事儿~() 还有个功能是数组的赋值:比如a=(1 3 5),那么${a[0]}=1;${a[1]}=3;${a[2]}=5,需要注意的是,下标是从0开始的。2.2 (()) 表达式计算a=1;((a++));echo $a,这时a就是2了。2.3 <() 和 >() 进程代入,可以把命令的执行结果当成文件一样读入比如comm前一般需要sort,那就可以这样comm <(sort 1.lst) <(sort 2.lst)或者是paste <(cut -t2 file1) <(cut -t1 file1),和管道差不多,但是支持多个输入。2.4 $() $(cmd) 执行cmd的结果,比如cmd是echo ls,那么就是执行ls,比如file $(which bash),which bash的结果是/bin/bash,所以file $(which bash)等于file /bin/bash。如果你$(ls),而且你的当前目录下只有a b两个文件,那么就是执行a b,然后系统会提示,命令没找到。$() 基本和 `` 等价。2.5 $(()) 表达式扩展,和(())很相似,但是这个是有点不同,$(())不能直接$((b++)),例如:b=1;echo $((++b))这时b等于2,显示的也是2,b=1; echo $((b++))这时b等于2,显示的是1.2.6 [] 和 [[]],[] 就是 test,[]和[[]]都是条件表达式,不过[[]]有比[]高的容错性,如果a为空,那么[ $a -eq 0 ]会报错,但是[[ $a -eq 0 ]]不会,所以一般都会使用[[]]或者是[ "$a" -eq 0 ],[[]]支持的功能也比 [] 多,比如[[ aaa =~ a{3} ]],[] 还有一种用途,如果你的当前目录下有a1-a9九个文件,你可以用a[1-9]来替代这九个文件。有点需要注意,你不能用a[1-20]来代替a1- a20,必须要a[1-9] a1[0-9] a20。但是需要注意的是 [[]] 数字进制转换的坑~2.7 $[] 是 $(()) 的过去形式,现在已经不建议使用。2.8 {n..m} {1..30} 就是1-30,或者是/{,s}bin/表示/bin/和/sbin/,ab{c,d,e}表示abc、abd、abe,小技巧:文件备份: cp a.sh{,.bak}而 { cmd1; cmd2; } 的作用是定义一个命令组,一般用在单行的条件表达式中: [[ 1 -eq 2 ]] && echo True || { echo False; echo "Program will exit!"; }其实 shell 函数的语法也是它的变体: a(){ i=$1; echo $((i++)); echo $((++i)); } && a 12.9 ${} 变量的Parameter Expansion,用法很多,最基本的 ${var}1,防止变量扩展冲突,具体可以查看man bash。或者参考我之前的博文链接:http://hi.baidu.com/leejun_2005/blog/item/ebfee11a4177ddc1ac6e751d.html3、bash 命令执行流程:执行分为四大步骤:输入、解析、扩展和执行。4、Refer:[1] shell 十三问之大括号参数扩展(Parameter Expansion)http://hi.baidu.com/leejun_2005/item/138c09343aaddff6e6bb7a49[2] shell 十三問? http://bbs.chinaunix.net/forum.php?mod=viewthread&tid=218853&page=7#[3] shell/bash 编程中各类括号的应用http://hi.baidu.com/leejun_2005/item/6f9eb7345e5f4f302f20c453[4] Bash Hackers Wiki Frontpage » Syntax » Parameter expansionhttp://wiki.bash-hackers.org/syntax/pe[5] 玩转 Bash 变量http://segmentfault.com/blog/spacewander/1190000002539169[6] Bash 快速入门指南http://blog.jobbole.com/85183/[7] SHELL (bash) 脚本编程六:执行流程https://segmentfault.com/a/1190000008215772
-
Linux命令-dd(device driver) dd,是 device driver 的缩写,它可以称得上是“Linux 世界中的搬运工”,它用来读取设备、文件中的内容,并原封不动地复制到指定位置。本文摘抄自(CSDN博主) 江湖有缘 当我们用 dd 命令读取 /dev/null 文件时,就可以创造出空洞文件,而如果你的磁盘足够大,你甚至可以创造出一个宇宙黑洞呢!一、备份磁盘并恢复之前看过一些介绍 dd 的文章,例子中基本都是使用 hda、hdb 这种 IDE 接口的硬盘,其实现在的主流硬盘已经是 SATA 接口的了,下面我要备份的硬盘是 dev/sda,它就是块 SATA 盘。dd if=/dev/sda of=/root/sda.img这个命令将 sda 盘备份到指定文件 /root/sda.img 中去,其中用到了如下两个选项:if=文件名:指定输入文件名或者设备名,如果省略“if=文件名”,则表示从标准输入读取。of=文件名:指定输出文件名或者设备名,如果省略“of=文件名”,则表示写到标准输出。通过上面的 dd 命令,我们得到了 sda.img 文件,它就是已经备份好了的磁盘映像文件,里面存储着 /dev/sda 整块硬盘的内容。在未来的某天,假如 /dev/sda 硬盘真的出现了故障,我们就可以将曾经备份的 sda.img 复制到另一台电脑上,并将其恢复到指定的 sdb 盘中去。dd if=/root/sda.img of=/dev/sdb如果能把目标硬盘直接连接到我们现在的电脑上,并让系统识别到这块新硬盘,例如识别成 /dev/sdc,那么我们可以直接使用 dd 命令将 sda 盘复制到 sdc 中去。这种用法既可以用来整盘备份,也可以用来快速复制系统环境。下面来看看具体的命令:dd if=/dev/sda of=/dev/sdc对 dd 来说,所有设备和文件都一视同仁,所谓的“备份”和“恢复”,dd 都认为是一种内容的复制。二、分区、内存、软盘一个都不能少如果只是想备份某一个分区的数据,操作如下:dd if=/dev/sda2 of=/root/sda_part1.img同理,将内存中的数据整体备份,照样可以如法炮制:dd if=/dev/mem of=/root/mem.img随着科技的飞速发展,无论是台式机还是笔记本,都已经取消了软驱和光驱设备,软盘和光盘也已经接近灭绝的边缘,很多九零后们应该都不知道软驱为何物了吧。所以接下来要介绍的软盘、光盘备份法:备份软盘dd if=/dev/fd0 of=/root/fd0.img count=1 bs=1440k备份光盘dd if=/dev/cdrom of=/root/cd.img对于 dd 命令来说,除了 if、of 两个选项之外,还应该掌握下面这两个重要选项:bs=N:设置单次读入或单次输出的数据块(block)的大小为 N 个字节。当然也可以使用 ibs 和 * obs 选项来分别设置。ibs=N:单次读入的数据块(block)的大小为 N 个字节,默认为 512 字节。obs=N:单次输出的数据块(block)的大小为 N 个字节,默认为 512 字节。count=N:表示总共要复制 N 个数据块(block)。所以这里备份的软盘大小是 1440kB,可以看出这是一块 3 寸盘,其大小为 1.44MB。全部选项#输入文件名,缺省为标准输入。 从file读取,如if=/dev/zero,该设备无穷尽地提供0,(不产生读磁盘IO) if=file #输出文件名,缺省为标准输出。 向file写出,可以写文件,可以写裸设备。如of=/dev/null,"黑洞",它等价于一个只写文件. 所有写入它的内容都会永远丢失. (不产生写磁盘IO) of=file #一次读入 bytes 个字节(即一个块大小为 bytes 个字节)。 ibs=bytes #一次写 bytes 个字节(即一个块大小为 bytes 个字节)。 obs=bytes #同时设置读写块的大小为 bytes ,可代替 ibs 和 obs。如bs=8k 每次读或写的大小,即一个块的大小为8K。 bs=bytes # 一次转换 bytes 个字节,即转换缓冲区大小。 cbs=bytes #从输入文件开头跳过 blocks 个块后再开始复制。 skip=blocks #从输出文件开头跳过 blocks 个块后再开始复制。(通常只有当输出文件是磁盘或磁带时才有效)。 seek=blocks #仅拷贝 blocks 个块,块大小等于 ibs 指定的字节数。 count=blocks #指定读的方式FLAGS,参见“FLAGS参数说明”oflag=FLAGS指定写的方式FLAGSflag=FLAGS #用指定的参数转换文件。 conv=conversion ascii:转换ebcdic为ascii ebcdic:转换ascii为ebcdic ibm:转换ascii为alternate ebcdic block:把每一行转换为长度为cbs,不足部分用空格填充 unblock:使每一行的长度都为cbs,不足部分用空格填充 lcase:把大写字符转换为小写字符 ucase:把小写字符转换为大写字符 swab:交换输入的每对字节 noerror:出错时不停止 notrunc:不截短输出文件 sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。 flags参数 三、使用 /dev/zero 和 /dev/null 来测试磁盘本段落开始前,先介绍下面两个参数:/dev/null,也叫空设备,小名“无底洞”。任何写入它的数据都会被无情抛弃。/dev/zero,可以产生连续不断的 null 的流(二进制的零流),用于向设备或文件写入 null 数据,一般用它来对设备或文件进行初始化。我们可以观察下面两个命令的执行时间,来计算出硬盘的读、写性能:向磁盘上写一个大文件, 来看写性能dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file从磁盘上读取一个大文件, 来看读性能dd if=/root/1Gb.file bs=64k | dd of=/dev/null上面命令生成了一个 1GB 的文件 1Gb.file,下面我们配合 time 命令,可以看出不同的块大小数据的写入时间,从而可以测算出到底块大小为多少时可以实现最佳的写入性能。time dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file time dd if=/dev/zero bs=2048 count=500000 of=/root/1Gb.file time dd if=/dev/zero bs=4096 count=250000 of=/root/1Gb.file time dd if=/dev/zero bs=8192 count=125000 of=/root/1Gb.file四、利用 /dev/urandom 进行格式化除了 /dev/null 和 /dev/zero 之外,还有一个很重要的文件,即 /dev/urandom,它是“随机数设备”,它的本领就是可以生成理论意义上的随机数。如果我们想清除硬盘里的某些机密数据,就可以使用 /dev/urandom 这个随机数生成器来产生随机数据,写到磁盘上,以确保将磁盘原始数据完全覆盖掉。dd if=/dev/urandom of=/dev/sda
-
chmod:给所有用户添加读或执行的权限 指令名称 : chmod 使用权限 : 所有使用者使用方式 : chmod [-cfvR] [--help] [--version] mode file...说明 : Linux/Unix 的档案调用权限分为三级 : 档案拥有者、群组、其他。利用 chmod 可以藉以控制档案如何被他人所调用。参数 :mode : 权限设定字串,格式如下 : ugoa...[rwxX]...][,...],其中u 表示该档案的拥有者,g 表示与该档案的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是。+ 表示增加权限、- 表示取消权限、= 表示唯一设定权限。 r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该档案是个子目录或者该档案已经被设定过为可执行。 -c : 若该档案权限确实已经更改,才显示其更改动作 -f : 若该档案权限无法被更改也不要显示错误讯息 -v : 显示权限变更的详细资料 -R : 对目前目录下的所有档案与子目录进行相同的权限变更(即以递回的方式逐个变更) --help : 显示辅助说明 --version : 显示版本范例 :将档案 file1.txt 设为所有人皆可读取 :chmod ugo+r file1.txt将档案 file1.txt 设为所有人皆可读取 :chmod a+r file1.txt将档案 file1.txt 与 file2.txt 设为该档案拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入 :chmod ug+w,o-w file1.txt file2.txt将 ex1.py 设定为只有该档案拥有者可以执行 :chmod u+x ex1.py将目前目录下的所有档案与子目录皆设为任何人可读取 :chmod -R a+r *此外chmod也可以用数字来表示权限如 chmod 777 file语法为:chmod abc file *其中a,b,c各为一个数字,分别表示User、Group、及Other的权限。r=4,w=2,x=1若要rwx属性则4+2+1=7;若要rw-属性则4+2=6;若要r-x属性则4+1=7。* 范例:chmod a=rwx file和chmod 777 file效果相同chmod ug=rwx,o=x file和chmod 771 file效果相同若用chmod 4755 filename可使此程序具有root的权限
-
spring cloud多环境配置文件 spring cloud多环境配置文件转载自: https://blog.csdn.net/yexiaomodemo/article/details/124045538 spring cloud用上了配置中心,就一个boostrap.yml,且不支持文件名的方式来区分。springcloud 配置中心bootstrap.yml区分环境的办法如下:boostrap.yml文件内容:spring: profiles: active: dev application: name: user-server swagger: api-title: 用户服务文档 url-pattern: /api/base/** feign: hystrix: enabled: true springfox: documentation: swagger: v2: path: /base/docs/info ##上面是基础配置,不用上配置中心那种 ##下面是环境区分,主要不同环境不同文件获取 --- #开发环境 spring: profiles: dev cloud: nacos: discovery: server-addr: localhost:8848 namespace: c97d4f46-deba-5588-b05f-c2a061ccc688 config: server-addr: localhost:8848 file-extension: yaml group: DEFAULT_GROUP namespace: c97d4f46-deba-5588-b05f-c2a061ccc688 --- #正式环境 spring: profiles: prod cloud: nacos: discovery: server-addr: localhost:8848 namespace: aa3de4c8-61ad-5568-9887-ed731659edd4 config: server-addr: localhost:8848 file-extension: yaml group: DEFAULT_GROUP namespace: aa3de4c8-61ad-5568-9887-ed731659edd4 --- #测试环境 spring: profiles: test cloud: nacos: discovery: server-addr: localhost:8848 namespace: 98adcdd5-f25c-7890-b8f3-97352adc83e8 config: server-addr: localhost:8848 file-extension: yaml group: DEFAULT_GROUP namespace: 98adcdd5-f25c-7890-b8f3-97352adc83e8多个配置以 --- 分开,然后通过spring.profiles=环境表示具体的环境配置.。三:java启动方式启动时可以指定我们的服务器上面的运行引用配置如:java -jar -Dspring.profiles.active=test *****.jar或者dockerfile启动方式ENTRYPOINT ["java","-jar","-Dspring.profiles.active=test","*****.jar"]